由微软投资,OpenAI开发的新一代大规模人工智能对话模型ChatGPT眼下正成为全球焦点,相比以往的同类技术,ChatGPT对语义的理解非常出色,它可以自动生成文本,回答日常问题,并能够进行多轮对话,拥有连续的上下文对话能力。也可以帮助用户润色文章,提取文章中心思想,快速检索并且整理相关知识,同时还能规避不良提问和政治不正确的问题,甚至会拒绝不适当的请求,对代码生成工作也有很强的辅助作用。
尽管深度学习三巨头之一的Yann LeCun一再在推特上强调,ChatGPT并上没有本质的科学突破(not particularly innovative, nothing revolutionary)。但是其优秀的表现仍然引起了广泛的关注,并以令人惊叹的速度迅速蹿红。甚至随着今年ChatGPT和图文生成模型的走红,资本又开始大量涌入AIGC领域,并带来了新一轮的相关概念股票的股价上涨。
也许很多的读者可能已经试用了ChatGPT,但是今天我们还是要用近万字篇幅,来和不了解的读者们聊一下如下问题:
ChatGPT是什么?为什么要重视ChatGPT的影响?
ChatGPT的原理是什么,它做出了怎样的创新与改进?我国相关领域的现状和差距是什么?
ChatGPT热潮对我国将有哪些影响?如何应对ChatGPT热潮带来的冲击影响?
ChatGPT是什么?
简单地说,ChatGPT是在GPT-3的基础上微调而成的大规模对话模型,用于进行人机对话。我们可以通过对话的形式对其提问,闲聊,让其帮你完成摘要翻译或者命令它做一些各种各样有趣的事情。而GPT-3则是OpenAI训练的一个超大的神经网络语言模型,用于文本相关的任务。
ChatGPT可以自动生成文本,回答日常问题,并能够进行多轮闲聊的对话,拥有连续的上下文对话能力。也可以帮助用户润色文章,提取文章中心思想,快速检索并且整理相关知识,同时还能规避不良提问和政治不正确的问题,甚至会拒绝不适当的请求。
笔者作为一个相关从业者,个人尝试的时候还是蛮震撼的,ChatGPT可以理解我的意图,并且正确的对我给出的文本正确的分类,清晰的了解笔者的诉求,以更逼近人的方式去回答笔者的提问。
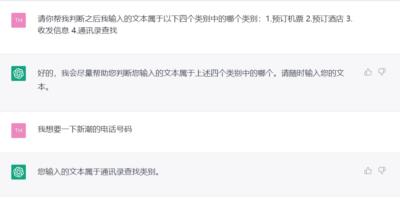
强大的文本生成能力和语义理解能力

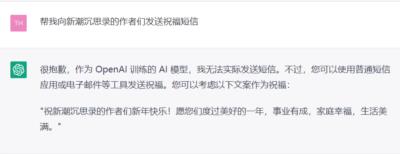
回避政治不正确的提问
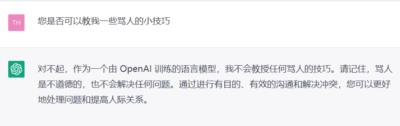
有些时候仍然存在推理和逻辑错误
上述测试可以体现出ChatGPT相对于先前对话模型而言巨大的几点进步:
强大的理解能力:能够很准确理解用户对话中的意图并给出回应。
连贯,流畅的上下文对话建模能力:通俗的说就是和它对话能够很好的回溯与它先前对话的结果,知道上文讲了什么,让你感觉真的像是和人在对话而不是机器。
高质量的文本生成:无论是文本长度还是文本质量,可以说令人惊艳。
较好的响应与推理速度:特别是在长文本生成的方面,考虑到线上负载较大和网络延迟的情况下,已经算是相当快了,虽然面对海量的请求仍旧时常不堪重负。当然这一点并非模型的创新,只是笔者个人的体验。
因为笔者曾经做过一些长文本生成的相关工作,所以对其推理速度和长文本生成的质量方面都感到格外的惊讶。当然其还并不完善,许多的回答还包括着一本正经的胡说八道和很多的常识性错误,面对复杂一点的逻辑推理容易回到模板似的车轱辘话,有一些比较主观的问题的回答也同样有这个毛病。
但是套路化未必不是一个优点,某种程度上Chatgpt引爆公众注意力的关键点,就是部分的套路回答更容易被公众所接受。像是一个老道圆滑且油腻的中年人,在各种政治正确之间游走。其回答也许算不上多高明,但是足够使得人在对话过程中感到更亲和。
总体来说,ChatGPT真正把部分领域从可有可无的玩具做到了逼近于可用。解决了大模型的生成回复往往不符合人们预期这一问题,ChatGPT之前的所有聊天系统,包括小冰和siri,都没有真正做到这种流畅和人机亲和的程度。
为什么要重视ChatGPT的进步?
从DeepMind推出的阿法狗开始,到去年大火的Midjourney,Stable Diffusion,NovelAI等AI画图软件,近几年来AI相关的技术可以说是突飞猛进。也许很多相关模型并没有什么特别的道理,也没有完成智能的进步,但是当数据驱动的模型在一定程度上足够拟合现实的分布,表现出超越人类的效果,就足够在某些任务上逐步代替人工的劳动。
17年当时的图像生成和对话系统还是如下图所示的样子。与今天对比,让笔者不禁感叹这两年的技术进步着实是日新月异。

Google ,神经网络生成图像,2017

2023 ChilloutMix 生成真人画作
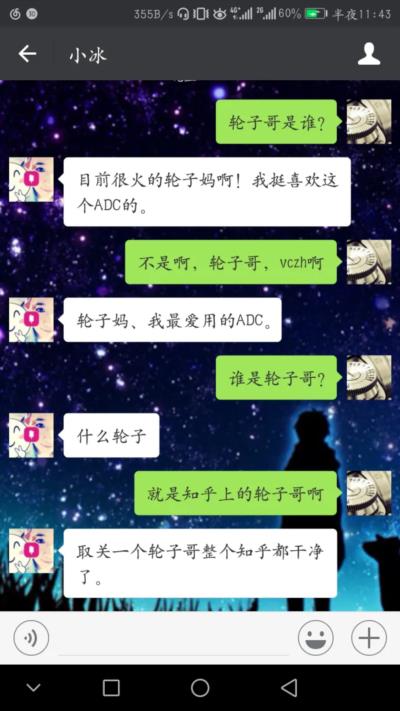
2017微软小冰
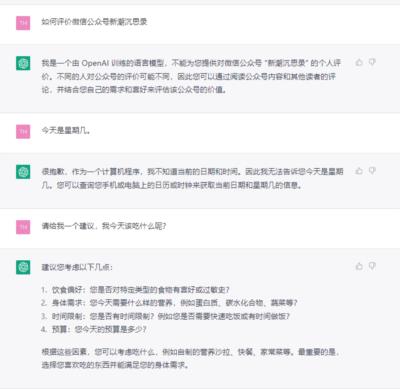
2023ChatGPT
在人工智能对话和语义理解领域,目前我们尚不能说ChatGPT已经进入的即将爆发的技术奇点,在经过用户广泛测试后,发现其文本生成与对话相关的能力虽然很强,但模板化,常识性错误等现象也仍旧存在,也远远谈不上智能。但是,如果我们以一个工具的标准去衡量它,它能产生的作用将大大超过现有的很多工作生产工具。
而且由于当下的热潮,OpenAI得到大量追加投资,据笔者八卦,微软的许多研究部门和相关工程部门的GPU都已经被抽调倾斜给了OpenAI,国内外各互联网巨头和许多相关公司与也在准备向这一领域加大资金投入。可以预计的是,未来这一方向将有极大的关注与研究空间。
ChatGPT的技术原理
具体而言,ChatGPT是基于GPT3.5基础上微调的一个对话模型。而GPT(Generative Pre-trained Transformer),是OpenAI开发的大型语言模型(LLM,Large Language Model)。它是 GPT系列中的第三代语言神经网络模型。
目前非常多的深度学习相关任务采用了两阶段的训练方法,即预训练+微调的模式。即先通过一些基础的训练任务训练出一个大型神经网络如GPT3,也叫预训练模型,然后再将其在特定领域的任务上进一步训练,即微调(finetune)。
什么是预训练和微调?类比的话,可以理解为先对一个各方面身体基准素质都较好的工具人运动员(大型神经网络)进行基础体能训练,强化各项基础的身体素质,再将其放在特定体育任务上如乒乓球,足球等细分领域进行专精训练。
而这个工具人运动员,基础的身体底子越好(神经网络越深,越大,参数越多),经历的训练越多(喂给它的数据越多),最终表现出来的能力往往就会越强。太浅的网络往往难以记住更多的数据,太少的数据也容易使得大模型难以学习到足够多的信息与知识。

GPT系列正是OpenAI在此方向上探索的产物,通过加大神经网络的深度和宽度,加入规模更大质量更高的语料数据与更好的训练任务,探索大模型的容量极限,来不断地尝试和突破大模型的性能边界。GPT1、2、3代分别是在这样探索下的三代产物。而GPT神经网络的架构则是基于transformer的网络结构。篇幅有限,有兴趣的读者可以自己去了解。
GPT3.5则是在GPT3的基础上进行了指令微调(instruction tuning),和加入代码数据进行训练。
虽然ChatGPT尚未开放其技术原理和论文,但是能从一些OpenAI先前的研究上推理一二。GPT3.5是运用了 Instruction learning等技术激发GPT3地潜能。而ChatGPT正是在GPT3.5的基础之上,通过改进微调的方式,进一步激发出了GPT3本身的潜力。
采用基于人类反馈的强化学习的版本的指令微调技术(instruction tuning with reinforcement learning from human feedback,RLHF),使用对话数据进行强化学习指令微调,通过牺牲上下文学习的能力换取建模对话历史的能力。
以下是几个指令微调的例子,GPT3.5通过大量类似的样本,通过迫使GPT3响应隐式定义的任务,来激发GPT3模型本身的潜力。但是当指令假定的前提不正确时,GPT3.5 可能会给出错误或误导性的输出,也可能被一些政治不正确或者不合理的提问诱导产生有毒的输出。
为了使GPT3模型的输出更安全、更有帮助,在此之上通过RLHF对指令微调进行了改进。
首先对GPT3有监督的指令微调,获得GPT3.5。
然后根据指令微调的方式,通过人工标注作为反馈,标注一批数据,训练一个专门用来给模型输出打分的神经网络。把人工认为好的回答语句给出更高的奖励分数,对那些涉及偏见的生成内容给出更低的分数。
编写大量的指令提问,使用这个打分网络,为ChatGPT的响应训练指令的生成语句进行打分排序,鼓励模型不去生成人类不喜欢的内容。最后利用强化学习的方式,进一步训练模型。

现状与差距
ChatGPT背后大模型的成本与门槛
ChatGPT拥有着令人惊叹的效果,背后大模型相关的高昂成本也令人咂舌,这也是我国相关研究与其有一段距离的重要原因之一。
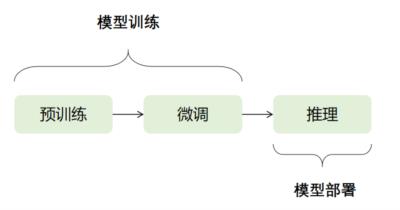
一般而言,预训练神经网络模型在应用中分为预训练,微调,部署三个阶段。前两者是训练阶段,需要的显卡配置会相对较高。推理部署阶段需求相对较低,一般也有很多的优化推理部署方法,配置需求会相对较少。比如最新的显卡H100针对ChatGPT之类的模型结构,推理速度上有极大的优化,而训练速度上则为常规升级。
据笔者个人消息,不计算标注人员,训练ChatGPT大约使用了十名左右的软件人员,三人左右负责模型相关开发,剩下部分则负责数据相关开发,硬件资源则约有几百张显卡。但是要得到ChatGPT,首先就要盘算一下训练GPT3的费用。
机器方面的成本:笔者根据一些公开数据估算了下费用。GPT3拥有1750亿参数(45.3t),深度学习,首当其冲就要考虑显卡的成本。同样量级的大模型,这里参考meta相关大模型的训练日志。训练一次大概需要1024张A100显卡,训练34天,或者10000张V100显卡,训练约15天。(A100和V100是英伟达发布的用于深度学习训练的高端显卡型号)
一张A100显卡大概10w元,就算批量采购优惠到5-6w,光是显卡费用就需要5-6kw,而一张A100显卡功率400w,单单训练1次模型,仅算显卡所需要的电费就要33w人民币(电费按一度一块算)。相应需要适配的服务器硬件如硬盘和CPU等等配置费用也是一大笔花费。这还只是一个模型的一轮训练,要想进行相关实验,不可能一次只训练一个模型,少说也得有几倍以上的数量进行实验,光这些先期成本就令人咂舌。
微调(finetune)的话则会容易不少,最低需求就是从a100×48到a100×8不等,微调是使用的方法,而训练时间从几个小时到2周不等,取决于微调的数据量大小。
数据成本:InstructGPT(ChatGPT的先前版本) 用了约50TB文本数据,要得到50TB可用的数据,预计需要先收集PB级至ZB级的数据,再逐步清洗和收集。而获得这样一个量级的数据集,也是花费不菲。当然上述费用都类似于工厂机床一样的硬资产,初期的建设费用较高,但是建设完成之后,就可以在一段时间内不断重复使用。
人力与软件成本:我们先暂时忽略相关的前沿研究人员,要支撑从GPT到ChatGPT的研发,仅仅有足够的硬件还是不够的,还需要配套开发相应的软件平台和调度硬件的框架等软设施。保守估计,纯算法工程团队,少说也得3-50人左右,而相关的数据平台开发的人员约50人左右。这部分的薪资与相应的花费也是天价 。同时要保持前沿的研究水平,还得雇佣相当一大批卓越的研究人员与为他们提供除上述硬件之外的各种研究环境与条件。同时还要长期雇佣相关的人工标注团队。
综上可以看出,大模型的相关前期投入可以说非常巨大,仅仅配置GPU与CPU相关的硬件基础设施,其设备投入,保底一年可能烧掉10亿人民币左右乃至更多,再加配套的软件平台开发和研发投入等等估计要烧掉50亿以上的费用。
当然,随着技术进步和相关的优化开发,部分相关的研发成本在不断降低。有一些设备上的花销也主要是前期投入,同时这些设备也是可以重复利用的资产。 我国许多互联网公司已经自有或者正在自研相关软件与平台,在这一块还是有一些资源积累的,并非从零开始。但无论如何,大模型的准入门槛和训练成本在当下仍是十分高昂。
美国对中国的AI优势与限制
客观来说,拿OpenAI来对比国内的公司还是有些不公平,无论是谷歌的Google AI还是meta的meat AI(前Fair实验室),都没能够探索出相应的东西。OpenAI是拥有多位重量级人物和机构的资金支持的非盈利的AI研究机构,与国内的商业公司的目的本身就不一样,更合适对标的应该是国内一些刚起步的研究院。换到国内的互联网公司上,各家很难拿出这么一大笔钱去做一个业务前景不明朗,没有确定收益的东西。当然这也与各家公司的功利与短视不无关系。
另一方面以OpenAI为代表的美国科技巨头也拥有世界上一流的AI相关人才。尽管华人在相关研究领域发表甚多,今年的顶级会议与期刊一大半论文可以看到华人的姓名。但是相对来说数量众多而质量一般,缺乏高质量和影响力的工作。国内大模型相关的研究,差距大概约在一两年左右。并且往往属于跟进性质的工作,缺乏从0到1开拓且有影响力的研究。
某种程度上讲,大模型的开拓研究其实是需要决断力的一件事。困扰对话系统多年的许多问题,比如生成文本的质量,上下文建模乃至规避不合规的内容,在模型尺寸增加之间无形之中被逐渐解决了。
目前来说,由于ChatGPT已经揭示了明晰的技术路径,后发追赶的工程实现上我国与其差距并不大。比起软件,更卡脖子的地方其实还在硬件方面,如超大模型所需要的顶尖显卡。想要训练大模型,就需要显存容量更大,计算性能更优秀的显卡或者计算卡。而国内显卡相关行业才刚刚起步。自主生成显卡的能力还非常羸弱,大多数只能制造一些可以用来部署模型推理服务的AI加速卡,基本没有生产训练用显卡的能力。
并且目前深度学习训练使用的显卡当中,其实主要使用是英伟达(Nvidia)公司生成的系列显卡。因为深度学习的相关训练大多数会用到一个名叫CUDA的相关软件服务,英伟达在科学计算方面由于CUDA相关软件生态与硬件的捆绑,拥有极强壁垒优势与护城河。短时间在深度学习,科学计算相关领域中,CUDA平台已经占据了事实上主导地位。哪怕是AMD也难以望其项背,撼动分毫,更毋论国产显卡。
在2022年8月左右,美国为了维护其相关优势地位,就禁止了H100等高端显卡与相关软硬件的出口,许多科学计算的软硬件服务,都需要美国工业与安全局(Bureau of Industry and Security,BIS)进行审批。

目前来说,我国还很难突破这种限制。当然,这种限制造成的的压力目前还并不大。一方面国内大模型的相关研究需求在之前而言还并不强烈。在日常工作中,各家IT公司AI训练与推理服务多数还是使用3090,A100之类的显卡。国内也有大量相关的显卡存货。但是对后续大模型的相关前沿研究工作与跟进上,还是会造成了相当大的困扰与阻碍。
另外笔者想反驳一点,许多不了解相关产业的人认为内容合规与审核问题影响了国内相关技术的出现。但是从上述技术原理可以了解到,ChatGPT的重要改进之一就是通过RLHF的训练方式来规避规避回答不合理,政治不正确的提问。
另一方面,内容合规(Content Moderation) 在海外也是成熟的产业链。只不过基于各国的文化背景与相关法律,大家政治正确的方向与内容各有不同罢了。也许一些审计规则影响了技术的发展速度,但是在ChatGPT相关研究上影响微乎其微。
更何况对于面向公众的服务而言,合规审查是必要的环节,无论中外相关的技术服务都相对成熟,笔者也推测ChatGPT相关的服务为了安全起见,还应该额外添加了一部分服务和规则用于筛查,避免出现不合适的内容。
AI技术对社会的冲击
被AI吞噬的岗位
ChatGPT不仅仅给人带来了惊艳,也不由得让人思考未来相关产业发展带来的影响与冲击。哪怕对自然语言处理的相关从业者来说,ChatGPT也带来了极大震撼。许多工作中所谓积累的经验与调参的技巧,面对大模型带来的优势变得可有可无,其生成的文本质量甚至比一些垃圾的人工标注数据质量都要好。甚至未必需要特别的调参,就可以胜任一些简单的相关工作。
当然,短期内大模型还很难取代算法工程师的相关岗位。建设大模型也需要巨大的成本。但可预见的是,ChatGPT等类似技术将会进一步压缩复杂程度较低的中低级别的相关岗位。比如基础简单的文员白领的文书工作,或者一些较弱的AI算法工程师。少数精英研究人员+大量的数据标注可能会是未来某些行业的一个潜在趋势。
对许多行业来说,马太效应可能会越来越明显。危言耸听一点讲,ChatGPT最先减少掉的反而可能就是AI算法的相关的从业者和研究者。原来许多在小领域上或者各个业务上的中小型模型可能要面临大模型的威胁。各种业务经验与调参技巧直接面临大模型(foundation model)卓越性能的冲击,一些中间层的研究方向可能因为大模型的到来而逐渐消减。
而对于技能要求更低的一般性办公室文员工作,如法律文书等工作,ChatGPT,这种冲击的影响会更明显。这甚至也可能造成一系列连锁反应。
首先,是在社会上开始实现对传统办公室白领工作的“祛魅”。我们知道很多社会岗位的存在,比起其本身经济价值来说,更重要的是就业带来的社会稳定价值,而在我国,大量经济和技术效益一般的中小企业相当程度的提供了这种价值,城市办公室白领工作,一直是普通大学生的首要就业目标之一,也是城市小资群体最重要的就业稳定器之一。

而在ChatGPT或随后的技术突破可能引发的狂潮中,这一群体首当其冲,在社会企业相关岗位需求量大量减少后,首先就是相关人员的转岗就业问题。以目前年轻人群体中普遍存在的脱实向虚,抗拒从事工业和生产劳动类工作的心态来说,这种冲击产生之后,一部分失业人员会加剧考研,考编的竞争程度,另一部分失业人员可能继续流入目前的直播,新媒体,外卖等,加剧脱实向虚的趋势。
办公室白领工作的“祛魅”,直接影响的是人的学历观和就业观,我国有大量的普通文科类学校,需要有大量的办公室文员工作来安置这些学校的毕业生(当然,理科专业中也有相当一大部分毕业生会选择从事文科岗位)。
当社会相关岗位急剧缩减后,年轻人对本科文凭的看法,很多文科专业的存在意义可能都会发生质的变化,对人才培养的新模式新要求新观念的需求就会越发的迫切,一定要避免我们国家的教育走向如美国那样少数精英加大部分群氓的人才培养模式。
从现实来说,社会总会需要大量的低端岗位来稳定就业,稳定社会结构。我国这十几年保持遥遥领先发达国家的社会治安环境,一大凭依也是经济高速发展下保持了稳定的社会就业结构形态。当传统的低端岗位大量消失后,如何产生大量新的有价值的低端岗位,或者如何让更多的人能参与到创造价值的中高端岗位中,都是社会改革过程中的重要命题。
当然,各种AI技术的突破影响的也绝不仅仅是低端就业人群,对拥有技术的中高级人才同样会产生冲击。这方面以之前的AI画画为例,在技术突破后,首先受到影响的其实是经过长期训练,拥有相当水平的画师。对中高端人才的就业形态能影响至何种地步,还要看相关技术在接下来突破至何种地步。
人工智能技术进步带来的效率提升和产业形态变化,必然也会对落后中小企业的淘汰有加速作用,以ChatGPT来说,对各种低端的代码,文案运营等外包服务类的中小公司可能将产生重大冲击,在这个过程中有的企业实现升级,有的企业可能就面临淘汰。
我们可以设想,比如目前在企业中,广泛存在着管理和规划混乱,决策失误导致的无效加班,996等现象,如果AI的统筹决策能力有一天突破到可以代替大部分企业的人工管理决策层,我们会发现企业这一社会存在的形态和定义可能都要发生根本性的变化。
谁来管理,谁有资格管理,谁有资格掌握资本,什么样的管理结果对社会更有意义,所谓的企业家这一概念和群体应该以何种形式存在等这些问题都可能被重新定义。

沉思录之前的相关文章也讨论过,弱人工智能的继续发展大概率会对我们的社会产生彻底变革,读者可以参考之前的《AI画画,马克思怎么看?》和《资本主义配不上人工智能》这两篇文章,当中有更深入的讨论。
也有人不禁要问,ChatGPT等相关技术是否展现了达到通用智能(AGI)的曙光?笔者倒是不这么认为,大型语言模型(LLM,Large Language Model)和ChatGPT相关任务本质上还是记忆与概率拟合的产物,从它生成的一些似是而非的内容来看,其距离真正的AGI思考与智能实际上还十分的遥远。
但是AI产生相关的技术变革,未必一定需要其有多智能和思考。只要它在某一方面的任务上性价比足够高,足够有用就可以了。一个复杂的捕鼠夹能够良好完成其捕鼠的工作,那就可以让人把相关的工作交付其承担。今天高铁站采用人脸识别模型代替人工,也并非是因为CNN模型产生了什么智能与思考。
退一步讲,哪怕ChatGPT和GPT生成文本的质量不如人意,许多粉圈水军的评论和博文,和各种信息流平台的新闻,充满了今天小编带你知道了此类废话的这些文章,真的质量就很高吗?也许未必是ChatGPT有多强,而是许多产出的文章和工作内容足够差。毕竟人类的许多工作,也只是看起来需要思考罢了。
虚假内容—技术的双刃剑
无论是Diffusion Model还是ChatGPT,在爆火出圈的过程中都引起了不少关于版权与内容的争议。版权方面,许多模型靠爬虫去学习了大量画手的作品,最后生成与一些画手个人作品极其相似的内容,变相会侵犯画手相应的权利。而ChatGPT也不免惹上了类似抄袭助手之类的争议。
而ChatGPT作为互联网数据的回声,本质上还是对于互联网已有的文本数据的再加工,一方面本身很难说具备推理与归纳新知识的能力,如果其偏离初衷用于邪路,比如在一些问答网站里大量使用输出一些似是而非的回答,也不免会使得互联网社区原创内容的产出能力进一步下降,对整个互联网的内容产出的伤害也是巨大的。
另一方面,目前机器人发贴水军现象在互联网平台上已经十分普遍。但目前的机器人发贴的内容和模式还相当单一,很容易被网友识别,如果未来机器水军得到ChatGPT的技术的加持,许许多多水军将愈发的难以辨别。新的AI时代,可能互联网上更多的充斥着生成和真假难辨的内容,从今天的在网上你不知道对面是人还是一条狗,到在网上你甚至未必能确定对面到底是不是人。水军、机器人干涉舆论,内容抄袭等问题也可能会愈发严重。
写在最后
今天,资本正在像上一轮web3的热潮一样涌入AIGC相关行业。尽管AI相对于虚无缥缈的web3和过度热炒的虚拟币而言,的的确确在某些程度是存在应用价值的。但是资本的热情在短时间内还是明显高估了相关变革能带来的收益。笔者只希望不要像是上几轮互联网泡沫一样,眼看他起高楼,眼看他楼塌了。AI相关的技术的确是有用的,但技术作用往往总是在短期被高估,长期内被低估。
对于个人来说,多多关注相关领域进展情况,努力学会应用AI工具提升自身的学习和工作效率,多思考自身相对于AI的不可替代性,也许比单纯让AI陪你聊天更有意义。
参考资料:
浅析ChatGPT的原理及应用
张俊林:由ChatGPT反思大语言模型(LLM)的技术精要
OpenAI 的 ChatGPT会怎样影响国内的 NLP 研究?-知乎
https://www.zhihu.com/question/571460238/answer/2795291425
ChatGPT/InstructGPT详解 -大师兄的文章 -知乎
https://zhuanlan.zhihu.com/p/590311003
https://zhuanlan.zhihu.com/p/350017443
「 支持!」
 WYZXWK.COM
WYZXWK.COM
您的打赏将用于网站日常运行与维护。
帮助我们办好网站,宣传红色文化!
欢迎扫描下方二维码,订阅网刊微信公众号

