目前,我国CPU发展存在自主研发和引进技术两条技术路线。
自主研发路线在硬件上基于自主定义指令集,基于自定义指令集或者主流指令集扩展,CPU自主设计,对于每一行代码,每个模块,每一条线都很清晰,在软件上自建生态。
引进技术路线是在硬件上基于买来的指令集授权或CPU源代码研制芯片,在软件上依附于西方成熟生态。
从实践上看,自主CPU比技术引进CPU更具发展后劲。
如何评价CPU
为了衡量CPU的性能,业界也推出了很多基准测试程序,比如针对CPU的SPEC,针对嵌入式应用的EEMBC等。SPEC测试是比较权威的测试程序。和一些黑箱测试程序调整计分方式和计分权重后测试结果就发生变化不同,SPEC测试到底跑了什么程序,以及各项程序跑分和计分方式全部公开透明,而且覆盖范围广——SPEC2000有12个定点程序,14个浮点程序,而且有比较强的代表性,比如gzip、vpr、gcc、mef、eon等。而SPEC2006则把定点程序扩展到14个定点程序和16个浮点程序。
在计分方法上,SPEC在计分上采用归一化的几何平均方法来进行综合性能评估。不过SPEC也非尽善尽美,测试存在容易受编译器影响的问题。举例来说,SUN曾经通过编译器优化提升SPEC跑分50%,龙芯的某一代产品也曾用自主研发的LCC编译器,比使用GCC定点跑分提升了60%。
另外,即便同样是GCC编译器,不同版本的GCC编译器下,测试成绩也会有很大差异。笔者认为,出现这种现象的根源并非SPEC测试的缺陷,反而用事实说明了,最后的用户体验是软件+硬件的结果,充分说明了软硬件磨合的重要性。
这里再谈一下编译器,程序员在编程的时候写的是编程语言,但是计算机运行的时候是机器语言,编译器就是将程序员的编程语言翻译成机器语言的工具。
此前,华为方舟编译器是舆论上非常火,一些媒体把编译器说的非常玄乎,仿佛"秒天秒地秒空气"。但这种宣传是有些过头了。方舟编译器是用于安卓平台,把java编译为机器码,和jit以及解释执行模式不同。和GCC、ICC(英特尔)、LCC(龙芯)、SWCC(申威)等PC编译器是两个不同概念。方舟编译器只对java有效,一位业内人士将其形容为:"方舟也是一种简单粗暴方法,以牺牲兼容性来换取局部性能提升,对手机局部性能有效,但生态兼容很麻烦"。

自主CPU单核性能进步速度优于技术引进CPU
目前,国内CPU公司在宣传上有一个非常不好的现象,那就是喜欢堆核心数,用64核、48核战平英特尔14核、28核CPU来"彰显"自己的CPU如何厉害。
但实际上,这种做法意义是相对有限的,因为在桌面和服务器,很多程序都是串行的,尤其是桌面CPU非常注重单核性能。
毕竟单核性能是基础,很多程序都依赖单进程的处理速度,如果单核性能上不去,核心数再多也没用,这也是在AMD推出锐龙以前,一大批六核、八核芯片打不赢Intel 四核芯片的原因。在电子发烧友中甚至还有"I3默秒全"的调侃,以及对联发科"1核有难,10核围观"的调侃。
游戏开发者也向AMD RTG图形部门大佬Raja Koduri表示:相比堆核心数,他们宁愿希望CPU单核性能提升1%。
类似的,一批国产ARM芯片虽然在PPT上追平英特尔,但市场上各个被英特尔吊打,只能时不时发一个PPT显示自己的存在感,甚至还不乏华芯通这种关门的例子。这背后的根源就在于如果单核性能不足,盲目堆核心数意义有限。
在AMD推出锐龙以后,单核性能大幅提升,这使AMD的市场份额有所回升,并使AMD的股价在2019年上涨80%,并去年在标普500指数中排名第一。值得一提的是,苏姿丰依靠锐龙,彻底打了一个翻身仗,在其担任CEO期间,AMD的股价上涨了800%。苏姿丰也凭此入选了美国金融报纸Barron发布的"2019年全球最佳CEO"名单。
因此,想要在市场上占据一席之地,单核性能至关重要,CPU单核性能不行的话,万事皆休。在日常使用中比较仰仗CPU定点性能,因而在这里我们以单线程实际测试的定点成绩做比较。
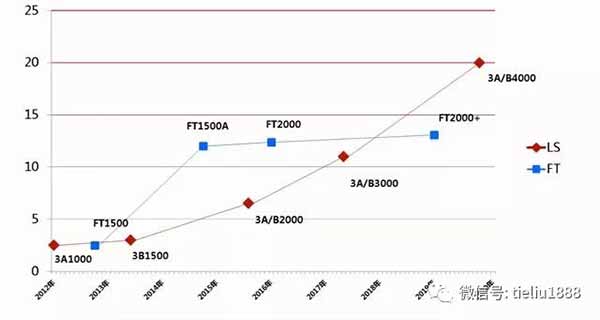
上图中,蓝色的为技术引进CPU,红色的为自主CPU。
先来看蓝色的技术引进 CPU。2013年的FT1500是基于SPARC的开源代码设计出来的,2015年的FT1500A为ARM,FT1500A相较于FT1500在单核性能上提升了4倍,但在FT1500A之后,FT2000和FT2000plus在单核性能上提升就比较有限了。
再来看红色的龙芯。龙芯3A1000和龙芯3B1500在单核性能上与FT1500大致相当。之后的龙芯3A/B2000明显逊色于FT1500A,之后的龙芯A3/B3000也只是在单核性能上接近FT2000。但到了龙芯3A/B4000这一代,性能有了大幅提升,单核性能提升超过80%。
根据公开消息,龙芯3A4000采用GS464V处理器核,支持LoongISA2.0指令集,支持256位向量扩展,支持核内安全机制,大幅提升同频通用性能。升级了片上互联网络,支持更多路片间互联,支持内存目录功能,提升I/O和多路性能。升级了访存接口,支持DDR4接口,制造工艺为28nm。
通过对样片的测试表明,龙芯单核定点和浮点性能均达到每Ghz频率10分(SPEC2006,GCC编译器),片内计算和访存能力均衡,开启向量的LINPACK核心效率超过93%。主频为1.8Ghz至2Ghz。
必须说明的是,龙芯3A/B4000这一代与龙芯A3/B3000这一代CPU在制造工艺上都是28nm SOI工艺,也就是说在制造工艺完全相同的情况下,龙芯通过自身的设计能力,把单核性能提升80%以上。在国内诸多ARM芯片性能提升高度依赖台积电先进工艺和购买国外更好EDA工具的大背景下,龙芯这种完全依靠自身设计能力提升CPU性能的做法绝对是一股清流。
之所以会产生这种现象,铁流认为,这主要是技术路线造成的。技术引进CPU虽然在初期会有一个大飞跃,但要实现技术引进消化吸收,这需要时间,会产生一个"先快后慢"的效果。目前,龙芯3A4000采用的依然是28nm工艺,在单核性能上已经追平或超越了国内一些采用7nm/16nm工艺的CPU,如果龙芯更新工艺,后续提升空间非常大。
CPU自主研发虽然在前期会有比较高的试错成本,发展也会慢一些,性能也会差一些,但有助于积累经验,锻炼能力。由于CPU源代码都是自己写的,发现问题后自己有能力改,通过不断的性能分析,找出CPU的瓶颈,然后不断地迭代,这才是发展的动力。
「 支持!」
 WYZXWK.COM
WYZXWK.COM
您的打赏将用于网站日常运行与维护。
帮助我们办好网站,宣传红色文化!
欢迎扫描下方二维码,订阅网刊微信公众号

